Factored language model
The factored language model (FLM) is an extension of a conventional language model introduced by Jeff Bilmes and Katrin Kirchoff in 2003. In an FLM, each word is viewed as a vector of k factors: 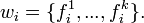 An FLM provides the probabilistic model
An FLM provides the probabilistic model 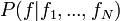 where the prediction of a factor
where the prediction of a factor 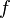 is based on
is based on  parents
parents 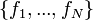 . For example, if
. For example, if 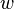 represents a word token and
represents a word token and 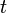 represents a Part of speech tag for English, the expression
represents a Part of speech tag for English, the expression 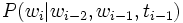 gives a model for predicting current word token based on a traditional Ngram model as well as the Part of speech tag of the previous word.
gives a model for predicting current word token based on a traditional Ngram model as well as the Part of speech tag of the previous word.
A major advantage of factored language models is that they allow users to specify linguistic knowledge such as the relationship between word tokens and Part of speech in English, or morphological information (stems, root, etc.) in Arabic.
Like N-gram models, smoothing techniques are necessary in parameter estimation. In particular, generalized back-off is used in training an FLM.
References
- J Bilmes and K Kirchhoff (2003). "Factored Language Models and Generalized Parallel Backoff" (PDF). Human Language Technology Conference.