Genetic algorithm scheduling
To be competitive, corporations must minimize inefficiencies and maximize productivity. In manufacturing, productivity is inherently linked to how well you can optimize the resources you have, reduce waste and increase efficiency. Finding the best way to maximize efficiency in a manufacturing process can be extremely complex. Even on simple projects, there are multiple inputs, multiple steps, many constraints and limited resources. In general a resource constrained scheduling problem consists of:
- A set of jobs that must be executed
- A finite set of resources that can be used to complete each job
- A set of constraints that must be satisfied
- Temporal Constraints–the time window to complete the task
- Procedural Constraints–the order each task must be completed
- Resource Constraints - is the resource available
- A set of objectives to evaluate the scheduling performance
A typical factory floor setting is a good example of this where scheduling which jobs need to be completed on which machines, by which employees in what order and at what time. In very complex problems such as scheduling there is no known way to get to a final answer, so we resort to searching for it trying to find a “good” answer. Scheduling problems most often use heuristic algorithms to search for the optimal solution. Heuristic search methods suffer as the inputs become more complex and varied. This type of problem is known in computer science as an NP-Hard problem. This means that there are no known algorithms for finding an optimal solution in polynomial time.
Genetic algorithms are well suited to solving production scheduling problems, because unlike heuristic methods genetic algorithms operate on a population of solutions rather than a single solution. In production scheduling this population of solutions consists of many answers that may have different sometimes conflicting objectives. For example, in one solution we may be optimizing a production process to be completed in a minimal amount of time. In another solution we may be optimizing for a minimal amount of defects. By cranking up the speed at which we produce we may run into an increase in defects in our final product.
As we increase the number of objectives we are trying to achieve we also increase the number of constraints on the problem and similarly increase the complexity. Genetic algorithms are ideal for these types of problems where the search space is large and the number of feasible solutions is small.
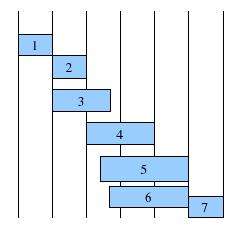
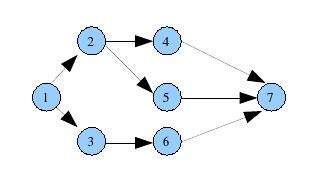
To apply a genetic algorithm to a scheduling problem we must first represent it as a genome. One way to represent a scheduling genome is to define a sequence of tasks and the start times of those tasks relative to one another. Each task and its corresponding start time represents a gene.
A specific sequence of tasks and start times (genes) represents one genome in our population. To make sure that our genome is a feasible solution we must take care that it obeys our precedence constraints. We generate an initial population using random start times within the precedence constraints. With genetic algorithms we then take this initial population and cross it, combining genomes along with a small amount of randomness (mutation). The offspring of this combination is selected based on a fitness function that includes one or many of our constraints, such as minimizing time and minimizing defects. We let this process continue either for a pre-allotted time or until we find a solution that fits our minimum criteria. Overall each successive generation will have a greater average fitness i.e. taking less time with higher quality than the preceding generations. In scheduling problems, as with other genetic algorithm solutions, we must make sure that we do not select offspring that are infeasible, such as offspring that violate our precedence constraint. We of course may have to add further fitness values such as minimizing costs however each constraint that we add greatly increases the search space and lowers the number of solutions that are good matches.
Bibliography
- Wall, M., A Genetic Algorithm for Resource-Constrained Scheduling (PDF)
- Lim, C.; Sim, E., Production Planning in Manufacturing/Remanufacturing Environment using Genetic Algorithm