Margin classifier
In machine learning, a margin classifier is a classifier which is able to give an associated distance from the decision boundary for each example. For instance, if a linear classifier (e.g. perceptron or linear discriminant analysis) is used, the distance (typically euclidean distance, though others may be used) of an example from the separating hyperplane is the margin of that example.
The notion of margin is important in several machine learning classification algorithms, as it can be used to bound the generalization error of the classifier. These bounds are frequently shown using the VC dimension. Of particular prominence is the generalization error bound on boosting algorithms and support vector machines.
Support vector machine definition of margin
See support vector machines and maximum-margin hyperplane for details.
Margin for boosting algorithms
The margin for an iterative boosting algorithm given a set of examples with two classes can be defined as follows. The classifier is given an example pair 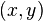 where
where 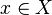 is a domain space and
is a domain space and 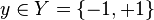 is the label of the example. The iterative boosting algorithm then selects a classifier
is the label of the example. The iterative boosting algorithm then selects a classifier 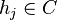 at each iteration
at each iteration  where
where 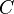 is a space of possible classifiers that predict real values. This hypothesis is then weighted by
is a space of possible classifiers that predict real values. This hypothesis is then weighted by 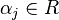 as selected by the boosting algorithm. At iteration
as selected by the boosting algorithm. At iteration 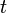 , the margin of an example
, the margin of an example 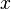 can thus be defined as
can thus be defined as
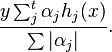
By this definition, the margin is positive if the example is labeled correctly and negative if the example is labeled incorrectly.
This definition may be modified and is not the only way to define margin for boosting algorithms. However, there are reasons why this definition may be appealing.[1]
Examples of margin-based algorithms
Many classifiers can give an associated margin for each example. However, only some classifiers utilize information of the margin while learning from a data set.
Many boosting algorithms rely on the notion of a margin to give weights to examples. If a convex loss is utilized (as in AdaBoost, LogitBoost, and all members of the AnyBoost family of algorithms) then an example with higher margin will receive less (or equal) weight than an example with lower margin. This leads the boosting algorithm to focus weight on low margin examples. In nonconvex algorithms (e.g. BrownBoost), the margin still dictates the weighting of an example, though the weighting is non-monotone with respect to margin. There exists boosting algorithms that provably maximize the minimum margin (e.g. see [2]).
Support vector machines provably maximize the margin of the separating hyperplane. Support vector machines that are trained using noisy data (there exists no perfect separation of the data in the given space) maximize the soft margin. More discussion of this can be found in the support vector machine article.
The voted-perceptron algorithm is a margin maximizing algorithm based on an iterative application of the classic perceptron algorithm.
Generalization error bounds
One theoretical motivation behind margin classifiers is that their generalization error may be bound by parameters of the algorithm and a margin term. An example of such a bound is for the AdaBoost algorithm.[1] Let 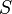 be a set of
be a set of 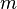 examples sampled independently at random from a distribution
examples sampled independently at random from a distribution 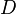 . Assume the VC-dimension of the underlying base classifier is
. Assume the VC-dimension of the underlying base classifier is 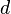 and
and 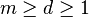 . Then with probability
. Then with probability 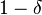 we have the bound
we have the bound
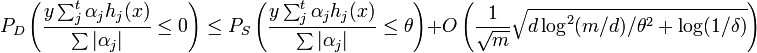
for all 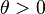 .
.
References
- 1 2 Robert E. Schapire, Yoav Freund, Peter Bartlett and Wee Sun Lee.(1998) "Boosting the margin: A new explanation for the effectiveness of voting methods", The Annals of Statistics, 26(5):1651–1686
- ↑ Manfred Warmuth and Karen Glocer and Gunnar Rätsch. Boosting Algorithms for Maximizing the Soft Margin. In the Proceedings of Advances in Neural Information Processing Systems 20, 2007, pp 1585–1592.