Mixing patterns
Mixing patterns refer to systematic tendencies of one type of nodes in a network to connect to another type. For instance, nodes might tend to link to others that are very similar or very different. This feature is common in many social networks, although it also appears sometimes in non-social networks. Mixing patterns are closely related to assortativity; however, for the purposes of this article, the term is used to refer to assortative or disassortative mixing based on real-world factors, either topological or sociological.
Types of Mixing Patterns
Mixing patterns are a characteristic of an entire network, referring to the extent for nodes to connect to other similar or different nodes. Mixing, therefore, can be classified broadly as assortative or disassortative. Assortative mixing is the tendency for nodes to connect to like nodes, while disassortative mixing captures the opposite case in which very different nodes are connected.
Obviously, the particular node characteristics involved in the process of creating a link between a pair will shape a network's mixing patterns. For instance, in a sexual relationship network, one is likely to find a preponderance of male-female links, while in a friendship network male-male and female-female networks might prevail. Examining different sets of node characteristics thus may reveal interesting communities or other structural properties of the network. In principle there are two kinds of methods used to exploit these properties. One is based on analytical calculations by using generating function techniques. The other is numerical, and is based on Monte Carlo simulations for the graph generation.[1]
In a study on mixing patterns in networks, M.E.J. Newman starts by classifying the node characteristics into two categories. While the number of real-world node characteristics is virtually unlimited, they tend to fall under two headings: discrete and scalar/topological. The following sections define the differences between the categories and provide examples of each. For each category, the models of assortatively mixed networks introduced by Newman are discussed in brief.
Mixing Based on Discrete Characteristics
Discrete characteristics of a node are categorical, nominal, or enumerative, and often qualitative. For instance, race, gender, and sexual orientation are commonly examined discrete characteristics.
To measure the mixing of a network on discrete characteristics, Newman[1] defines a quantity 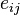 to be the fraction of edges in a network that connect nodes of type i to type j (see Fig. 1). On an undirected network this quantity is symmetric in its indices
to be the fraction of edges in a network that connect nodes of type i to type j (see Fig. 1). On an undirected network this quantity is symmetric in its indices 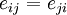 , while on directed ones it may be asymmetric. It satisfies the sum rules
, while on directed ones it may be asymmetric. It satisfies the sum rules
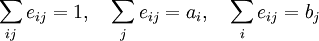 ,
,
where 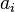 and
and 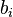 are the fractions of each type of an edge's end that is attached to nodes of type
are the fractions of each type of an edge's end that is attached to nodes of type 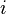 . On undirected graphs, where there is no physical distinction between the ends of a link, i.e. the ends of edges are all of the same type,
. On undirected graphs, where there is no physical distinction between the ends of a link, i.e. the ends of edges are all of the same type, 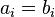 .
.
Then, an assortativity coefficient, a measure of the similarity's or dissimilarity's strength between two nodes on a set of discrete characteristics may be defined as:
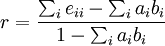
with
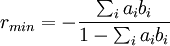
This formula yields 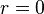 when there's no assortative mixing, since
when there's no assortative mixing, since 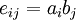 in that case, and
in that case, and  when the network is perfectly assortative. If the network is perfectly disassortative, i.e. every link connects two nodes of different types, then
when the network is perfectly assortative. If the network is perfectly disassortative, i.e. every link connects two nodes of different types, then 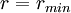 , which lies in general in the range
, which lies in general in the range 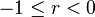 . This range for
. This range for  implies that a perfectly disassortative network is normally closer to a randomly mixed network than a perfectly assortative one is. When there are several different types of nodes, then random mixing will most often pair unlike nodes, so that the network appears to be mostly disassortative. Therefore, it is appropriate that the value for a random network should be closer to that for the perfectly disassortative network than for the perfectly assortative one.
implies that a perfectly disassortative network is normally closer to a randomly mixed network than a perfectly assortative one is. When there are several different types of nodes, then random mixing will most often pair unlike nodes, so that the network appears to be mostly disassortative. Therefore, it is appropriate that the value for a random network should be closer to that for the perfectly disassortative network than for the perfectly assortative one.
The method of generating functions is based on the idea of figuring out the proper generating function for the distributions of our interest every time, and extract data related to the networks structure by differentiating them. Assuming that the degree distribution 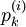 for nodes of type and the value of the matrix (and hence, the values of and ) are known, then we may consider the ensemble of all graphs with the specified and to yield collective (macroscopic) network characteristics. In principle, the generating function for and its first moment are given by
for nodes of type and the value of the matrix (and hence, the values of and ) are known, then we may consider the ensemble of all graphs with the specified and to yield collective (macroscopic) network characteristics. In principle, the generating function for and its first moment are given by
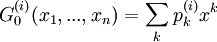 , and
, and
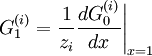 ,
where
,
where 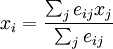 the node of type (
the node of type (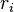 in the number) and
in the number) and 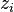 the mean degree for nodes of this type. Now we focus on the distributions that we're interested for.
the mean degree for nodes of this type. Now we focus on the distributions that we're interested for.
The distribution of the total number of nodes reachable by following an edge that arrives at a node of type has a generating function
![H_{1}^{(i)}(x) = xG_{1}^{(i)}[H_{1}^{(1)}(x),...,H_{1}^{(n)}(x)]](../I/m/c54dcfb5a9d7afe6050592b703a2fea3.png) .
Similarly, the distribution of the number of nodes reachable from a randomly chosen node of type is generated by
.
Similarly, the distribution of the number of nodes reachable from a randomly chosen node of type is generated by
![H_{0}^{(i)}(x) = xG_{0}^{(i)}[H_{1}^{(1)}(x),...,H_{1}^{(n)}(x)]](../I/m/492aba1799d0fd28e4983259a87b3c04.png) .
Now we are in position to yield some of the network's properties. The mean number
.
Now we are in position to yield some of the network's properties. The mean number 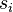 of nodes reachable from a node of type is
of nodes reachable from a node of type is
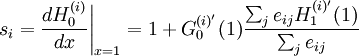
Furthermore, if 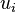 is the probability for a node of type (reached by following a randomly chosen link in the graph) not to belong to the giant cluster, then the overall fraction
is the probability for a node of type (reached by following a randomly chosen link in the graph) not to belong to the giant cluster, then the overall fraction 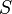 of nodes that compose this cluster is given by
of nodes that compose this cluster is given by
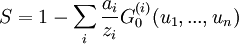
The numerical simulations based on Monte Carlo techniques seem to agree with the analytical results yielded by the formulas described above.
Mixing by Scalar or Topological Characteristics
Scalar characteristics of a node are those that are quantitative. They may be continuous or discrete ordinal variables like counts. Age is perhaps the simplest example, though intelligence and raw income are other obvious possibilities. Some topological features of the network may also be used for examining mixing by scalar properties. Specifically, the degree of a node is often a highly important feature in the mixing patterns of networks.[2] Topological scalar features are very useful, because unlike other measures, they are always available. They are sometimes used as a proxy for real-world "sociability".[1]
For measuring the assortativity of scalar variables, similar to the discrete case (see above) an assortativity coefficient can be defined. One can measure it using the standard Pearson Correlation, as Newman demonstrates.[1] In Fig. 2, for instance, a calculation of the Pearson Correlation Coefficient yields r = 0.574. This indicates a fairly strong association between the age of husbands and wives at the time of marriage.
An alternative coefficient can be computed for measuring the mixing by the degree of the nodes. Newman [1] derives the expression, which is found to be
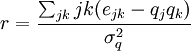 for an undirected network. In this formula, if
for an undirected network. In this formula, if 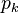 refers to the graph's degree distribution (i.e., the probability that a node has degree k) then
refers to the graph's degree distribution (i.e., the probability that a node has degree k) then 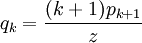 . This refers to the excess degree of a node, or the number of other edges aside from the currently examined one. The z refers to the average degree in the network, and
. This refers to the excess degree of a node, or the number of other edges aside from the currently examined one. The z refers to the average degree in the network, and 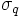 is the standard deviation of the distribution
is the standard deviation of the distribution 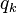 . For a directed network the equivalent expression is
. For a directed network the equivalent expression is
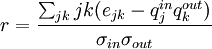 .
.
This correlation is positive when nodes are assortative by degree, and negative when the network is disassortative. Thus, the measure captures an overall sense of the mixing patterns of a network. For a more in-depth analysis of this topic, see the article on assortativity.
The method of generating functions is still applicable for this case too, but the functions to be calculated are rarely calculable in closed form. Thus, numerical simulations seem to be the only way to yield results of some interest. The technique used is once again the Monte Carlo one. For the case of networks with a power-law degree-distribution 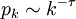 ,
, 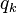 has a divergent mean, unless
has a divergent mean, unless 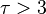 , which rarely happens so.[3] Instead, the exponentially truncted power-law distribution
, which rarely happens so.[3] Instead, the exponentially truncted power-law distribution
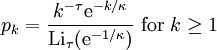 yields a distribution for the excess degree of the type
yields a distribution for the excess degree of the type 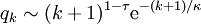 . The results for this case are summarized below.
. The results for this case are summarized below.
1) The position of the phase transition at which a giant cluster appears moves to higher values of 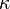 as the value of
as the value of  decreases. That is, the more assortative a network is, the lower the edge density threshold for the giant cluster's appearance will be.
decreases. That is, the more assortative a network is, the lower the edge density threshold for the giant cluster's appearance will be.
2) The size of the giant cluster in the limit of large is smaller for the assortatively mixed graph, than for the neutral and disassortative ones.
3) Assortative mixing in the network affects the network's robustness under node removal. For assortative networks, it is required to remove about ten times more than usual (usual means a neutral network) high-degree nodes to destroy the giant cluster, while the opposite is true for disassortative networks, i.e. they are more susceptible than neutral ones under removal of the high-degree nodes.
The fascinating result on the dependence of the network's robustness to its node mixing may be explained as follows. According to their definition, high-degree nodes in assortative networks tend to form a core group among them. Such a core group provides robustness to the network by concentrating all the obvious target nodes together in one portion of the graph. Removing these high-degree nodes is still one of the most effective ways to destroy network connectivity, but it is less effective (compared to neutral networks) because by removing them all from the same portion of the graph we fail to attack other portions. If these other portions are themselves percolating, then a giant cluster will persist even as the highest degree nodes vanish. On the other hand, the disassortatively mixed network is particularly susceptible to removal of high-degree nodes because these nodes are strewn far apart across the network, so that attacking them is like attacking all parts of the network at once.
Examples and Applications
A common application of mixing patterns is the study of disease transmission. For instance, many studies have used mixing to study the spread of HIV/AIDS and other contagious diseases.[4][5][6] These articles find a strong connection between Mixing patterns and the rate of disease spread. The findings can also be used to model real-world network growth, as in,[7] or find communities within networks.
References
- 1 2 3 4 5 Newman, M.E.J., Mixing patterns in networks. Phys. Rev. E 67, 026126 (2003).
- ↑ Newman, M.E.J., Assortative mixing in networks. Phys. Rev. Lett. 89, 208701 (2002).
- ↑ Albert R. and Barabási A.-L., Statistical mechanics of complex networks, Rev. Mod. Phys. 74, 47–97 (2002)
- ↑ S O Aral, J P Hughes, B Stoner, W Whittington, H H Handsfield, R M Anderson, and K K Holmes. "Sexual mixing patterns in the spread of gonococcal and chlamydial infections." Am J Public Health. 89, pp. 825–833 (1999) .
- ↑ Garnett GP, Hughes JP, Anderson RM, Stoner BP, Aral SO, Whittington WL, Handsfield HH, and Holmes KK.. "Sexual mixing patterns of patients attending sexually transmitted diseases clinics." Sex Transm Dis. 23, pp. 248-57 (1996).
- ↑ Ford, Kathleen, Woosung Sohn, and James Lepowski. "American adolescents: sexual mixing patterns, bridge partners, and concurrency." Sex Transm Dis. 29, pp. 13-19 (2002).
- ↑ Catanzaro, Michele, Guido Caldarelli, and Luciano Pietronero. Social network growth with assortative mixing. Physica A 338 (2004).