Nested set model
The nested set model is a particular technique for representing nested sets (also known as trees or hierarchies) in relational databases. The term was apparently introduced by Joe Celko; others describe the same technique using different terms.[1] [2]
Motivation
The technique is an answer to the problem that the standard relational algebra and relational calculus, and the SQL operations based on them, are unable to express all desirable operations on hierarchies directly. A hierarchy can be expressed in terms of a parent-child relation - Celko calls this the adjacency list model - but if it can have arbitrary depth, this does not allow the expression of operations such as comparing the contents of hierarchies of two elements, or determining whether an element is somewhere in the subhierarchy of another element. When the hierarchy is of fixed or bounded depth, the operations are possible, but expensive, due to the necessity of performing one relational join per level. This is often known as the bill of materials problem.
Hierarchies may be expressed easily by switching to a graph database. Alternatively, several resolutions exist for the relational model and are available as a workaround in some relational database management systems:
- support for a dedicated hierarchy data type, such as in SQL's hierarchical query facility;
- extending the relational language with hierarchy manipulations, such as in the nested relational algebra.
- extending the relational language with transitive closure, such as SQL's CONNECT statement; this allows a parent-child relation to be used, but execution remains expensive;
- the queries can be expressed in a language that supports iteration and is wrapped around the relational operations, such as PL/SQL, T-SQL or a general-purpose programming language
When these solutions are not available or not feasible, another approach must be taken.
The technique
The nested set model is to number the nodes according to a tree traversal, which visits each node twice, assigning numbers in the order of visiting, and at both visits. This leaves two numbers for each node, which are stored as two attributes. Querying becomes inexpensive: hierarchy membership can be tested by comparing these numbers. Updating requires renumbering and is therefore expensive. Refinements that use rational numbers instead of integers can avoid renumbering, and so are faster to update, although much more complicated.[3]
Example
In a clothing store catalog, clothing may be categorized according to the hierarchy given on the left:

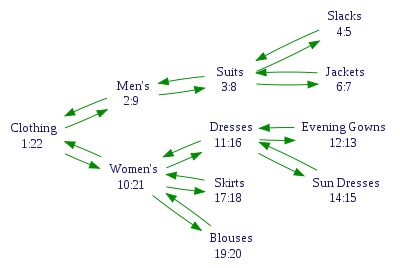
| Node | Left | Right |
|---|---|---|
| Clothing | 1 | 22 |
| Men's | 2 | 9 |
| Women's | 10 | 21 |
| Suits | 3 | 8 |
| Slacks | 4 | 5 |
| Jackets | 6 | 7 |
| Dresses | 11 | 16 |
| Skirts | 17 | 18 |
| Blouses | 19 | 20 |
| Evening Gowns | 12 | 13 |
| Sun Dresses | 14 | 15 |
The "Clothing" category, with the highest position in the hierarchy, encompasses all subordinating categories. It is therefore given left and right domain values of 1 and 22, the latter value being the double of the total number of nodes being represented. The next hierarchical level contains "Men's" and "Women's", both containing levels within themselves that must be accounted for. Each level's data node is assigned left and right domain values according to the number of sublevels contained within, as shown in the table data.
Performance
Queries using nested sets can be expected to be faster than queries using a stored procedure to traverse an adjacency list, and so are the faster option for databases which lack native recursive query constructs, such as MySQL.[4] However, recursive SQL queries can be expected to perform comparably for 'find immediate descendants' queries, and much faster for other depth search queries, and so are the faster option for databases which provide them, such as PostgreSQL,[5] Oracle,[6] and Microsoft SQL Server.[7]
Drawbacks
Nested sets are very slow for inserts because it requires updating left and right domain values for all records in the table after the insert. This can cause a lot of database thrash as many rows are rewritten and indexes rebuilt. However, if it is possible to store a forest of small trees in table instead of a single big tree, the overhead may be significantly reduced, since only one small tree must be updated.
The nested interval model does not suffer from this problem, but is more complex to implement, and is not as well known. The nested interval model stores the position of the nodes as rational numbers expressed as quotients (n/d).
Variations
Using the nested set model as described above has some performance limitations during certain tree traversal operations. For example, trying to find the immediate child nodes given a parent node requires pruning the subtree to a specific level as in the following SQL code example:
SELECT Child.Node, Child.Left, Child.Right
FROM Tree as Parent, Tree as Child
WHERE
Child.Left BETWEEN Parent.Left AND Parent.Right
AND NOT EXISTS ( -- No Middle Node
SELECT *
FROM Tree as Mid
WHERE Mid.Left BETWEEN Parent.Left AND Parent.Right
AND Child.Left BETWEEN Mid.Left AND Mid.Right
AND Mid.Node NOT IN (Parent.Node AND Child.Node)
)
AND Parent.Left = 1 -- Given Parent Node Left Index
Or, equivalently:
SELECT DISTINCT Child.Node, Child.Left, Child.Right
FROM Tree as Child, Tree as Parent
WHERE Parent.Left < Child.Left AND Parent.Right > Child.Right -- associate Child Nodes with ancestors
GROUP BY Child.Node, Child.Left, Child.Right
HAVING max(Parent.Left) = 1 -- Subset for those with the given Parent Node as the nearest ancestor
The query will be more complicated when searching for children more than one level deep. To overcome this limitation and simplify tree traversal an additional column is added to the model to maintain the depth of a node within a tree.
| Node | Left | Right | Depth |
|---|---|---|---|
| Clothing | 1 | 22 | 0 |
| Men's | 2 | 9 | 1 |
| Women's | 10 | 21 | 1 |
| Suits | 3 | 8 | 2 |
| Slacks | 4 | 5 | 3 |
| Jackets | 6 | 7 | 3 |
| Dresses | 11 | 16 | 2 |
| Skirts | 17 | 18 | 2 |
| Blouses | 19 | 20 | 2 |
| Evening Gowns | 12 | 13 | 3 |
| Sun Dresses | 14 | 15 | 3 |
In this model, finding the immediate children given a parent node can be accomplished with the following SQL code:
SELECT Child.Node, Child.Left, Child.Right
FROM Tree as Child, Tree as Parent
WHERE
Child.Depth = Parent.Depth + 1
AND Child.Left > Parent.Left
AND Child.Right < Parent.Right
AND Parent.Left = 1 -- Given Parent Node Left Index
See also
References
- ↑ Recursive Dimension Hierarchies: The Relational Taboo by Michael Kamfonas originally published at the Relational Journal in 1992
- ↑ Storing Hierarchical Data in a Database: Modified Pre-order Tree Traversal, by Gijs van Tulder, at articles.sitepoint.com
- ↑ Hazel, Daniel. "Using rational numbers to key nested sets". arXiv:0806.3115
 .
. - ↑ Quassnoi (29 September 2009), "Adjacency list vs. nested sets: MySQL", Explain Extended, retrieved 11 December 2010
- ↑ Quassnoi (24 September 2009), "Adjacency list vs. nested sets: PostgreSQL", Explain Extended, retrieved 11 December 2010
- ↑ Quassnoi (28 September 2009), "Adjacency list vs. nested sets: Oracle", Explain Extended, retrieved 11 December 2010
- ↑ Quassnoi (25 September 2009), "Adjacency list vs. nested sets: SQL Server", Explain Extended, retrieved 11 December 2010
External links
- Troels' links to Hierarchical data in RDBMSs
- Managing hierarchical data in relational databases
- PHP PEAR Implementation for Nested Sets - by Daniel Khan
- Transform any Adjacency List to Nested Sets using MySQL stored procedures