Hermite distribution
|
Probability mass function 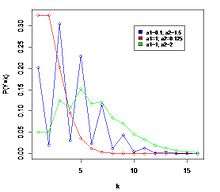 The horizontal axis is the index k, the number of occurrences. The function is only defined at integer values of k. The connecting lines are only guides for the eye. | |
|
Cumulative distribution function 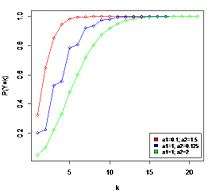 The horizontal axis is the index k, the number of occurrences. The CDF is discontinuous at the integers of k and flat everywhere else because a variable that is Hermite distributed only takes on integer values. | |
| Notation | |
|---|---|
| Parameters | a1 ≥ 0, a2 ≥ 0 |
| Support | x ∈ { 0, 1, 2, ... } |
| pmf | |
| CDF | |
| Mean | |
| Variance | |
| Skewness | |
| Ex. kurtosis | |
| MGF | |
| CF | |
| PGF | |


![{\displaystyle x\mapsto e^{-a_{1}+a_{2}}\sum _{i=0}^{\lfloor x\rfloor }\sum _{j=0}^{[i/2]}{\frac {a_{1}^{i-2j}a_{2}^{j}}{(i-2j)!j!}}}](../I/m/217fc1b470d33b624987345955b1e40ec58dfcfd.svg)







In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data. The Hermite distribution is a special case of the Poisson binomial distribution, when n = 2.
The authors Kemp and Kemp [1] have called it "Hermite distribution" from the fact its probability function and the moment generating function can be expressed in terms of the coefficients of (modified) Hermite polynomials.
History
The distribution first appeared in the paper Applications of Mathematics to Medical Problems,[2] by Anderson Gray McKendrick in 1926. In this work the author explains several mathematical methods that can be applied to medical research. In one of this methods he considered the bivariate Poisson distribution and showed that the distribution of the sum of two correlated Poisson variables follow a distribution that later would be known as Hermite distribution.
As a practical application, McKendrick considered the distribution of counts of bacteria in leucocytes. Using the method of moments he fitted the data with the Hermite distribution and found the model more satisfactory than fitting it with a Poisson distribution.
The distribution was formally introduced and published by C. D. Kemp and Adrienne W.Kemp in 1965 in their work Some Properties of ‘Hermite’ Distribution. The work is focused on the properties of this distribution for instance a necessary condition on the parameters and their maximum likelihood estimators (MLE), the analysis of the probability generating function (PGF) and how it can be expressed in terms of the coefficients of (modified) Hermite polynomials. An example they have used in this publication is the distribution of counts of bacteria in leucocytes that used McKendrick but Kemp and Kemp estimate the model using the maximum likelihood method.
Hermite distribution is a special case of discrete compound Poisson distribution with only two parameters.[3][4]
The same authors published in 1966 the paper An alternative Derivation of the Hermite Distribution.[5] In this work established that the Hermite distribution can be obtained formally by combining a Poisson distribution with a normal distribution.
In 1971, Y. C. Patel[6] did a comparative study of various estimation procedures for the Hermite distribution in his doctoral thesis. It included maximum likelihood, moment estimators, mean and zero frequency estimators and the method of even points.
In 1974, Gupta and Jain[7] did a research on a generalized form of Hermite distribution.
Definition
Probability mass function
Let X1 and X2 be two independent Poisson variables with parameters a1 and a2. The probability distribution of the random variable Y = X1 + 2X2 is the Hermite distribution with parameters a1 and a2 and probability mass function is given by [8]
![{\displaystyle p_{n}=P(Y=n)=e^{-a_{1}+a_{2}}\sum _{j=0}^{[n/2]}{\frac {a_{1}^{n-2j}a_{2}^{j}}{(n-2j)!j!}}}](../I/m/9af7f646d06b890ef76758d7bbb8b5cc855e4454.svg)
where
- n = 0, 1, 2, ...
- a1, a2 ≥ 0.
- (n − 2j)! and j! are the factorials of (n − 2j) and j, respectively.
- [n/2] is the integer part of [n/2].
The probability generating function of the probability mass is,[8]

Notation
When a random variable Y = X1 + 2X2 is distributed by an Hermite distribution, where X1 and X2 are two independent Poisson variables with parameters a1 and a2, we write

Properties
Moment and cumulant generating functions
The moment generating function of a random variable X is defined as the expected value of et, as a function of the real parameter t. For an Hermite distribution with parameters X1 and X2, the moment generating function exists and is equal to

The cumulant generating function is the logarithm of the moment generating function and is equal to [4]

If we consider the coefficient of (it)rr! in the expansion of K(t) we obtain the r-cumulant

Hence the mean and the succeeding three moments about it are
| Order | Moment | Cumulant |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 | ||
| 4 |








Skewness
The skewness is the third moment centered around the mean divided by the 3/2 power of the standard deviation, and for the hermite distribution is,[4]

- Always , so the mass of the distribution is concentrated on the left.

Kurtosis
The kurtosis is the fourth moment centered around the mean, divided by the square of the variance, and for the Hermite distribution is,[4]

The excess kurtosis is just a correction to make the kurtosis of the normal distribution equal to zero, and it is the following,

- Always , or the distribution has a high acute peak around the mean and fatter tails.


Characteristic function
In a discrete distribution the characteristic function of any real-valued random variable is defined as the expected value of , where i is the imaginary unit and t ∈ R

![\phi (t)=E[e^{{itX}}]=\sum _{{j=0}}^{\infty }e^{{ijt}}P[X=j]](../I/m/d4964c0b9f61587ea0535d23122324cc61f76416.svg)
This function is related to the moment-generating function via . Hence for this distribution the characteristic function is,[1]


Cumulative distribution function
The cumulative distribution function is,[1]
![{\begin{aligned}F(x;a_{1},a_{2})&=P(X\leq x)\\&=\exp(-(a_{1}+a_{2}))\sum _{{i=0}}^{{\lfloor x\rfloor }}\sum _{{j=0}}^{{[i/2]}}{\frac {a_{1}^{{i-2j}}a_{2}^{j}}{(i-2j)!j!}}\end{aligned}}](../I/m/c96c5ebef779e27f599767ce2533a53305c8da6d.svg)
Other properties
- This distribution can have any number of modes. As an example, the fitted distribution for McKendrick’s [2] data has an estimated parameters of , . Therefore, the first five estimated probabilities are 0.899, 0.012, 0.084, 0.001, 0.004.



- This distribution is closed under addition or closed under convolutions.[9] As the Poisson distribution, the Hermite distribution has this property. Given 2 random Hermite variables and , then Y = X1 + X2 follows an Hermite distribution, .
- This distribution allows a moderate overdispersion, so it can be used when data has this property.[9] A random variable has overdispersion, or it is overdispersed with respect the Poisson distribution, when its variance is greater than its expected value. The Hermite distribution allows a moderate overdispersion because the coefficient of dispersion is always between 1 and 2,




Parameter estimation
Method of moments
The mean and the variance of the Hermite distribution are and , respectively. So we have these two equation,



Solving these two equation we get the moment estimators and of a1 and a2.[6]




Since a1 and a2 both are positive, the estimator and are admissible (≥ 0) only if, .

Maximum likelihood
Given a sample X1, ..., Xm are independent random variables each having an Hermite distribution we wish to estimate the value of the parameters and . We know that the mean and the variance of the distribution are and , respectively. Using these two equation,
![{\displaystyle {\begin{cases}a_{1}=\mu (2-d)\\[4pt]a_{2}={\dfrac {\mu (d-1)}{2}}\end{cases}}}](../I/m/c366a33fdbf13d1a9560c1b3cbd9822e7baee8f6.svg)
We can parameterize the probability function by μ and d
![P(X=x)=\exp \left(-\left(\mu (2-d)+{\frac {\mu (d-1)}{2}}\right)\right)\sum _{{j=0}}^{{[x/2]}}{\frac {(\mu (2-d))^{{x-2j}}\left({\frac {\mu (d-1)}{2}}\right)^{j}}{(x-2j)!j!}}](../I/m/9c90e2a499001f61245d7139f8ae5733faeb612a.svg)
Hence the log-likelihood function is,[9]

where
![q_{i}(\theta )=\sum _{{j=0}}^{{[x_{i}/2]}}{\frac {\theta ^{j}}{(x_{i}-2j)!j!}}](../I/m/8b52aa6a4a705c175b8a62d5074c8b70cd6fd426.svg)

From the log-likelihood function, the likelihood equations are,[9]


Straightforward calculations show that,[9]
- And d can be found by solving,


where

- It can be shown that the log-likelihood function is strictly concave in the domain of the parameters. Consequently, the MLE is unique.
The likelihood equation does not always have a solution like as it shows the following proposition,
Proposition:[9] Let X1, ..., Xm come from a generalized Hermite distribution with fixed n. Then the MLEs of the parameters are and if only if , where indicates the empirical factorial momement of order 2.




- Remark 1: The condition is equivalent to where is the empirical dispersion index
- Remark 2: If the condition is not satisfied, then the MLEs of the parameters are and , that is, the data are fitted using the Poisson distribution.




Zero frequency and the mean estimators
A usual choice for discrete distributions is the zero relative frequency of the data set which is equated to the probability of zero under the assumed distribution. Observing that and . Following the example of Y. C. Patel (1976) the resulting system of equations,


We obtain the zero frequency and the mean estimator a1 of and a2 of ,[6]


where , is the zero relative frequency, n > 0

It can be seen that for distributions with a high probability at 0, the efficiency is high.
- For admissible values of and , we must have

Testing Poisson assumption
When Hermite distribution is used to model a data sample is important to check if the Poisson distribution is enough to fit the data. Following the parametrized probability mass function used to calculate the maximum likelihood estimator, is important to corroborate the following hypothesis,

Likelihood-ratio test
The likelihood-ratio test statistic [9] for hermite distribution is,

Where is the log-likelihood function. As d = 1 belongs to the boundary of the domain of parameters, under the null hypothesis, W does not have an asymptotic distribution as expected. It can be established that the asymptotic distribution of W is a 50:50 mixture of the constant 0 and the . The α upper-tail percentage points for this mixture are the same as the 2α upper-tail percentage points for a ; for instance, for α = 0.01, 0.05, and 0.10 they are 5.41189, 2.70554 and 1.64237.


The "score" or Lagrange multiplier test
The score statistic is,[9]
![S_{2}=2m\left[{\frac {m^{{(2)}}-{\bar {x}}^{2}}{2{\bar {x}}}}\right]^{2}={\frac {m({\tilde {d}}-1)^{2}}{2}}](../I/m/18e914d56c5ff3cbc680ee7a7a30da3a79b5d8e1.svg)
where m is the number of observations.
The asymptotic distribution of the score test statistic under the null hypothesis is a distribution. It may be convenient to use a signed version of the score test, that is, , following asymptotically a standard normal.

See also
References
- 1 2 3 Kemp, C.D; Kemp, A.W (1965). "Some Properties of the "Hermite" Distribution". Biometrika. 52 (3-4): 381–394. doi:10.1093/biomet/52.3-4.381.
- 1 2 McKendrick, A.G. (1926). "Applications of Mathematics to Medical Problems". Proceedings of the Edinburgh Mathematical Society. 44: 98–130. doi:10.1017/s0013091500034428.
- ↑ Huiming, Zhang; Yunxiao Liu; Bo Li (2014). "Notes on discrete compound Poisson model with applications to risk theory". Insurance: Mathematics and Economics. 59: 325–336. doi:10.1016/j.insmatheco.2014.09.012.
- 1 2 3 4 Johnson, N.L., Kemp, A.W., and Kotz, S. (2005) Univariate Discrete Distributions, 3rd Edition, Wiley, ISBN 978-0-471-27246-5.
- ↑ Kemp, ADRIENNE W.; Kemp C.D (1966). "An alternative derivation of the Hermite distribution". Biometrika. 53 (3-4): 627–628. doi:10.1093/biomet/53.3-4.627.
- 1 2 3 Patel, Y.C (1976). "Even Point Estimation and Moment Estimation in Hermite Distribution". Biometrics. 32 (4): 865–873. doi:10.2307/2529270. JSTOR 2529270.
- ↑ Gupta, R.P.; Jain, G.C. (1974). "A Generalized Hermite distribution and Its Properties". SIAM Journal on Applied Mathematics. 27: 359–363. doi:10.1137/0127027. JSTOR 2100572.
- 1 2 Kotz, Samuel (1982–1989). Encyclopedia of statistical sciences. John Wiley. ISBN 0471055522.
- 1 2 3 4 5 6 7 8 Puig, P. (2003). "Characterizing Additively Closed Discrete Models by a Property of Their Maximum Likelihood Estimators, with an Application to Generalized Hermite Distributions". Journal of the American Statistical Association. 98: 687–692. doi:10.1198/016214503000000594. JSTOR 30045296.